DeepSeek命运预演:无证者的天空

通过开源其模型,DeepSeek为任何好奇的开发者提供了学习和在节约成本的创新基础上进行开发的机会。虽然开源人工智能的定义仍在不断发展中,但DeepSeek通过发布其代码、模型和技术报告,符合行业普遍接受的开源定义。
这正是开源的理想:在全球研发者构建的沙箱中自由交换思想,允许聪明和富有创意的想法相互融合。
开源模型的支持者认为,开源可以加速科学和创新,改善透明度,分散治理权力,并增强市场竞争力。然而,在人工智能(AI)社区中,关于开源与闭源的辩论仍在激烈进行。
到目前为止,一家公司很难找到一个明确的、短期内有商业价值的理由,来支撑自己选择开源其AI模型。从“让互补品标准化”的角度来看,Meta公司的做法是有道理的,但这一逻辑并不适用于像DeepSeek这样的纯粹AI实验室。
在中国的科技领域,这种务实的观点较为常见。百度创始人李彦宏就曾直言不讳地表示:开源其实是一种智商税。
“当你理性地去想,大模型能够带来什么价值,以什么样的成本带来价值的时候,就会发现,你永远应该选择闭源模型。今天无论是ChatGPT、还是文心一言等闭源模型,一定比开源模型更强大,推理成本更低。”
“开源模型打不过闭源模型。你只要理性的去看待,你的收益是啥,你的成本是啥,你就会发现,最好还是去选择闭源模型。”
财力雄厚的阿里巴巴公司虽然维持着其开源的Qwen模型,但其通过向客户推销API、云服务和计算基础设施来赚钱。李开复的初创公司01.AI发布了Yi-34B,作为“反哺”中国开发者社区的方式,但该公司最终以最先进的专有模型为基础,作为其商业产品的基础。
相比之下,DeepSeek在短期内没有明确的盈利策略和计划。
在 2023 年的一次采访中,CEO 梁文锋表示“DeepSeek的目标是推动技术前沿,而不是快速商业化”。这种观点让人想起 OpenAI 的创始人 Sam Altman 在 2019 年的那句名言:“我不知道我们将来如何产生收入。”为 DeepSeek 提供资金的量化对冲基金幻方量化公司强调,其 AI 模型研究不会用于股票交易:
“这与金融无关……我们关心的是长期的社会价值。”
我们应该相信这些原则性的表态——这不是一个政府背景的项目,因为DeepSeek的运作方式与传统的中国政府支持的行业截然不同。更准确地说,DeepSeek的员工主要由年轻的本土人才组成,是由除了赚钱之外的某些动力来驱动的。
一位采访者询问梁文峰“你们在做一件很疯狂的事吗?”,他的回答则十分有意思:
“不知道是不是疯狂,但这个世界存在很多无法用逻辑解释的事,就像很多程序员,也是开源社区的疯狂贡献者,一天很累了,还要去贡献代码。类似你徒步50公里,整个身体是瘫掉的,但精神很满足。”
“不是所有人都能疯狂一辈子,但大部分人,在他年轻的那些年,可以完全没有功利目的,投入地去做一件事。”
这些年轻的中国开发者对开源项目的强烈热情,有时被称为“开源情怀”。大多数工程师都会感到兴奋,如果自己的开源项目——无论是数据库、容器注册表等——被一家外国公司,尤其是硅谷的公司采用。他们会在已经免费的软件基础上,再无偿付出劳动,日夜修复bug、解决问题,一切都是为了获得认可与肯定。
在这种“热忱”或“使命感”之中,隐含着一种深刻的意识:西方根本不尊重他们的工作,因为在外界看来,中国的一切要么是偷来的,要么是靠作弊得来的。
他们也清楚,许多中国公司一直在免费利用开源技术发展自身,但他们渴望自己去创造、去贡献,并证明自己的技术足够优秀,值得被外国企业免费采用——其中既有民族情结,也有作为工程师的自豪感。
在最近的一次采访中,梁文峰也表达了类似的看法。他解释说,对顶级人才吸引最大的,肯定是去解决世界上最难的问题。“顶尖人才在中国是被低估的。因为整个社会层面的硬核创新太少了,使得他们没有机会被识别出来。我们在做最难的事,对他们就是有吸引力的。”
这一情况如今正在改变。得益于最近的开源模型,DeepSeek已经赢得了全球工程师的认可与尊重。
然而,监管者会以同样的眼光看待它吗?
中国政府已经对开源发展表达了一定程度的支持。2018年,中国人工智能开源软件发展联盟成立,使开源AI进入了公众视野。一份官方背景的白皮书指出,开源生态的建立需要通过培育开源社区和人才、推动标准制定、建立资金支持机制、完善知识产权体系以及加强安全审查等手段来实现。
国家层面的政策规划
监管层对国内开源社区的积极态度,主要是因政界和产业界须减少对外国软件依赖的需求。
中国政府在 2000 年代初推动开源发展,建立了多个开源软件联盟,并推出自主操作系统(中科红旗(Red Flag Linux))的研发,以此来削弱 Microsoft Windows 操作系统的影响力。此后,工业和信息化部将Gitee指定为中国的国家级“独立开源代码托管平台”。
在中国的芯片产业,开源项目正被视为降低对国外封闭生态系统依赖的一种途径。指令集架构(ISA)是芯片硬件与计算机上运行的软件之间的接口。美国的英特尔和英国的ARM公司长期以来提供大多数芯片使用的闭源指令集架构,这使得这些公司能够获得丰厚的利润。
开源经济对单个公司来说仍然充满挑战,中国尚未为开源指令集架构(ISA)开发推出类似于芯片产业其他领域的“大基金”。然而,私营和公共领域的兴趣种子已经开始发芽:除了华为、阿里巴巴等巨头在为微控制器(MCU)和中央处理器(CPU)投资开源ISA外,一些不太知名的公司,如VeriSilicon(芯原股份)、江苏云涌科技、Bluetrum(中科蓝讯)、C*Core Technology(国芯科技)等,也在利用开源RISC-V、Linux和Khronos生态系统开展研究项目,开发物联网应用、自然语言处理、神经网络、自动驾驶汽车等解决方案。
2019年,华为消费者软件部门总裁曾警告称,如果没有自己的开源社区,“一旦发生我们无法控制的情况,中国所有的软件社区都将面临巨大风险。”
那么,监管层是否会允许DeepSeek团队继续他们充满激情的“技术秀”呢?尽管官方言辞积极,但人工智能技术可能带来的潜在责任风险,可能会促使其不乐于拥抱开源。
操作系统无法像人工智能那样将信息和权力传播到公众手中。但是,一个开源的AI模型能给予公众广泛的访问、使用和定制权限——这些是难以被有效监控或撤回的。
而且,AI的安全风险也显而易见。随着AI技术的不断进步,其创造的将不仅仅局限于一个过于直言不讳的聊天机器人。事实上,我们离这样的世界并不遥远,不妨大胆想象,在AI驱动的未来世界里,如果风险隔离屏障没有得到加强,那么有人就可以下载某些东西或在某个云服务器上启动程序,对某人的生活或关键基础设施造成真正的损害。
目前,中国的生成式AI法规还缺乏对开源提供者的具体指导。随着监管机构在国家控制需求与创新雄心之间寻求平衡,DeepSeek团队——更多受到好奇心和激情驱动,而非眼前利润——可能处于一个脆弱的位置。
但是,无论如何,至少在目前,监管层看到的依然是开源AI的潜在好处。
DeepSeek的成功激发了中国更多关于开源优势的讨论。中国的AI初创公司MiniMax发布了多个开源模型,期望“对优秀的工作给予鼓励,对不好的工作给予批评,外界的人也能够作出贡献。”中国分析人士指出,具有成本效益的开源模型能够支持广泛的访问和采用,尤其是在全球南方国家。
一位工程师发布了一份传播广泛的文章,他在文章中驳斥了Anthropic公司的首席执行官Dario关于DeepSeek和出口管制的文章:
Dario提出了一个关键问题:如果中国在2026–2027年获得数百万台高端GPU,会发生什么?他的回答是——如果中国无法获得这些计算资源,美国将进入“单极AI主导”阶段,并可能通过AI的自我强化机制,长期巩固其优势。然而,如果中国确实获得了这些资源,美国可能面临一场持久的“AI军备竞赛”。
我的看法是:无论是单极还是双极,AI发展已经不可逆转地进入了全球扩散的阶段。美国不会垄断AI,中国也不会被遏制,像欧洲、日本、印度等国家也不会袖手旁观。出口管制、模型竞争和资本流动等变量可能会影响竞争的节奏,但它们无法阻止世界朝着更先进的AI形式迈进。
DeepSeek不是终点,而是一个信号——它的意义不在于“击败”任何人,而在于证明世界已经进入了一个不可逆转的大规模AI竞争时代。
在思考DeepSeek时,两个观点可能同时成立:
DeepSeek可能选择开源其模型,和世界各地的开发者选择开源一样,是因为对开放、全球研究社区的价值有着真诚的信仰——他们希望展示自己的成就,并激励他人基于其工作的基础进行构建。
与此同时,随着AI模型变得愈加强大,政府监管层可能会有动力介入并掌握控制权。
除了政府的直接干预,DeepSeek的成就将为企业合作伙伴打开大门,提供比目前DeepSeek所拥有的计算能力更为庞大的资源。DeepSeek没有外部投资者,没有顶级西方实验室的海归学者,也没有政府合同或流行的消费级应用。这种情况将会改变。正如OpenAI在推出ChatGPT后与微软合作的例子一样,中国的顶级云计算公司——字节跳动、阿里巴巴、腾讯和华为——将会主动接触。
考虑到梁云峰的硬核创新承诺和他对计算资源不足的坦承,他可能不会放弃在研发中获得额外算力资源的机会。这可能会将DeepSeek推向真正推动创新前沿的方向,与西方的主要AI参与者展开竞争。
一个问题留给未来:开源AI在中国的未来如何?算力资源的吸引力会不会使DeepSeek偏离其开源理念?监管层会不会为了安全和控制介入?
雪贝财经组建了已拥有超过两千名组员的社群,他们主要来自于地产公司、金融机构、一线互联网公司,以及FA机构。如果你希望获取所有专供独家信息,并与这些来自于金融、地产投资、科技领域的高净值人群交流,在公众号对话框回复“星球”。
推荐阅读

DeepSeek搅动产业链
“我们打算招募更多的闲置算力”,在接入DeepSeek-R1之后,青云科技市场总监王玉圆向北京商报记者透露,在她看来,“这波连锁反应中,最早受益的是上游的算力公司”。


盯上DeepSeek炙手的流量,有人开始赚钱了
春节前,一条“蓝色鲸鱼”横空出世,DeepSeek(深度求索)以大约十分之一的训练成本,推出与OpenAI o1性能接近的开源模型R1,小力出奇迹,搅动AI圈一池春水。


京东云发布DeepSeek大模型一体机,内置多种AI行业应用
京东云重磅发布DeepSeek大模型一体机,基于“本地化开箱即用”的理念,提供全栈解决方案,为客户打造“数据不出域、性能更高效”的AI服务新范式。


DeepSeek开拓AI行业共赢局面,关注两大潜力投资主线
近日,中国AI初创公司深度求索(DeepSeek)先后发布了DeepSeek-V3和DeepSeek-R1两款大模型,成本价格低廉,性能与OpenAI相当,引起AI业内广泛高度关注。

“收割”消费者!流量投机客借势DeepSeek牟利35万,平台最新回应
DeepSeek仍在持续走红,顶流之下,有闻风而动迅速反应的各类平台,有嗅到机会蜂拥接入的各路企业,当然,更多的还是不知其为何物的一众普通用户。
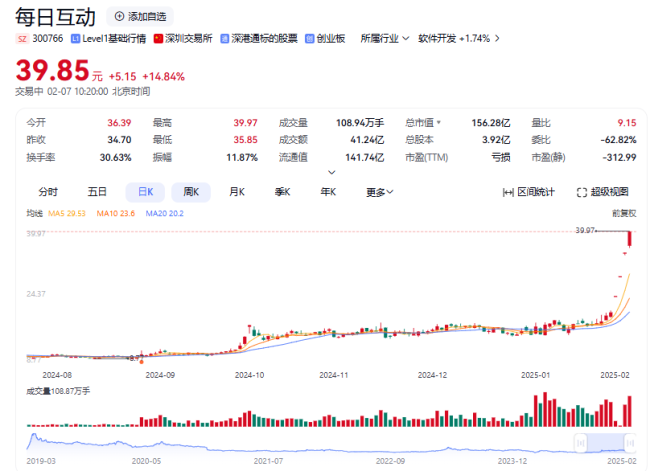

封锁下成长起来的中国AI“三叉戟”,为何让大洋彼岸的硅谷恐慌?
无论是Deepseek的开源模型打破“算力垄断”,还是萝卜快跑用1/7的成本碾压Waymo,中国AI的崛起直指美国技术霸权的软肋——当硅谷沉迷于资本堆砌的军备竞赛时,中国企业用工程化创新和场景化落地开辟了一条新赛道。
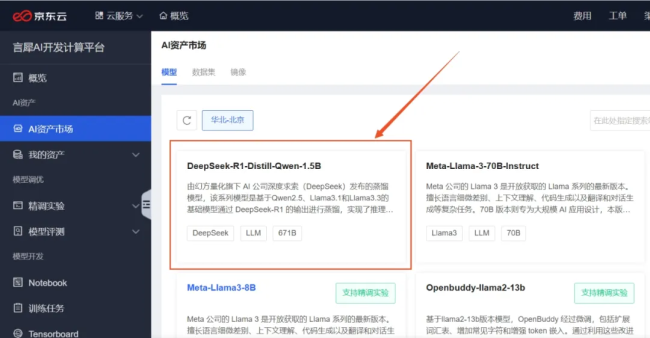
一键部署!京东云全面上线DeepSeek-R1/V3
京东云已正式上线DeepSeek-R1和DeepSeek-V3模型,支持公有云在线部署、专混私有化实例部署两种模式,供用户按需部署,快速调用。

“健康小美”AI智能主检批量上线,美年健康引领行业变革
蛇年的第一个交易周,在国产AI大模型DeepSeek崛起的加持下,国内AI 链条以及科技股的地位被重估。