清华学霸创办的智谱,估值200亿,却被DeepSeek抢了风头?
作为全球AI领域的黑马,DeepSeek成功搅乱了中国AI大模型市场的格局。科技大厂们选择合作,接入其模型疯抢用户;而AI独角兽们则陷入两难境地,上演了“Do Or Die”的抉择。
其中,有着“大模型六小虎”之称的六家AI独角兽公司(智谱AI、百川智能、月之暗面、MiniMax、阶跃星辰及零一万物),纷纷开始转型:
2025年伊始,李开复的零一万物宣布转型,不再追逐超大模型,而是聚焦AI商业化应用;紧接着,消息称百川智能放弃B端金融市场,聚焦AI医疗;月之暗面开始削减Kimi的投流预算,重新规划大模型发展方向;MiniMax的B端业务频繁调整,逐步将重心移向C端。
在此情况下,智谱AI(以下简称智谱)成为今年首个拿到新一轮风投的AI独角兽公司,因此备受关注。2025年3月,智谱开启D轮融资,投资方包括杭州城投、上城资本等,金额超10亿元。
但市场瞬息万变,唯一不变的就是变化。就在智谱刚刚获得新一轮投资时,中国AI市场又出现了新的血液:一个名为Monica的杭州团队,做出了号称“全球首个通用Agent”的 Manus。暂不讨论其是创新还是营销,Manus迅速引爆舆论登上热搜,成功出圈。与此同时,腾讯元宝取代DeepSeek登顶AppStore中国区免费下载榜榜首,则充分说明大厂资源之雄厚,投流不计成本。
在越来越严苛的市场环境下,智谱能否找到新的风口,讲好中国AI故事?
清华团队做大模型,估值200亿
AI企业讲究“基因”,而智谱显然是其中最优秀的尖子生。智谱脱胎于清华大学知识工程研究室,创始人团队成员均是清华学霸,天使轮投资者之一也是清华大学资管。
智谱首席科学家、创始人唐杰,曾任清华大学计算机系教授、系副主任等职务,深耕数据挖掘和机器学习领域,发表了200余篇论文,带领团队成功打造出中国首个且世界规模之最的1.75万亿参数大规模预训练模型WuDao 2.0。
作为初始核心团队的一员,张鹏更为人熟知,目前担任智谱CEO职务。基本上,产品发布会、参与活动及访谈,都能看到张鹏的身影。张鹏同样是清华大学计算机博士,参与了智谱的主要产品包括GLM系列大模型、AMiner、XLORE等项目的研发工作。
2019年6月,智谱正式成立,主公司是北京智谱华章科技有限公司。张鹏、刘德兵和王绍兰作为合伙人创立宁波慧惠企业管理合伙企业(有限合伙),以10.8995%股份比例作为大股东控股智谱;唐杰则是智谱的最大自然人股东,企查查显示其持股比例7.5077%。
值得一提的是,智谱的股东阵容十分豪华,除了中关村科学城、大兴投资、深圳达晨地方性国企,还包括蚂蚁集团、顺为资本、腾讯投资等互联网资本,以及老牌VC/PE机构红杉中国、高瓴创投等。
据公开资料统计,截至2025年3月3日,智谱已经进行了至少7轮融资,募集资金超150亿元,在C+轮时估值达到了200亿元。最新D轮投资者中,杭州城投、上城资本两大杭州政府投资平台的加入备受关注,毕竟杭州是DeepSeek(深度求索)的大本营。

清华学霸团队、国企背书,智谱无疑是AI独角兽中最具光环的一个。但现实是,它并未像DeepSeek一样出圈。复盘其中的原因,除了营销因素之外,技术路线的不同也是关键。
卷参数、卷工具,却打不过DeepSeek
回顾一下智谱大模型的发展历程,会发现在走传统路线(卷参数)的同时,还伴有部分局部创新,如多模态、多工具调用、算力优化等。张鹏曾在多个公开场合表示,智谱更倾向于大模型,而不是垂直领域的小模型。
2021年9月,智谱团队设计了GLM算法,并推出100亿参数的开源大模型GLM-10B。GLM算法的优势是改进了空白填充预训练,在自然语言理解任务上超越了谷歌制定的BERT 和 T5算法。
随后,智谱对大模型产品进行逐步升级和细分化,包括千亿参数的GLM-130B、ChatGLM对话模型以及多模态模型产品矩阵。2023年8月,智谱清言AI助手上线,代表着智谱正式进入C端市场。
2023年3月,智谱发布千亿参数对话模型ChatGLM即开源版本ChatGLM-6B,该模型的提升除了参数部分,还加入了跨平台硬件支持,除了英伟达显卡,还包括华为昇腾、海光、神威等国产卡,缓解算力紧张的情况。
进入2024年,智谱最强大模型GLM-4发布,张鹏亲自站台,详解了该模型的技术突破。性能方面,GLM-4在基准性能测试中比肩GPT-4,并将重点放在多模态“All Tools”概念,即模型自动选择工具,可实现文图生产、代码解释器、网页浏览等。同年6月,智谱又发布了GLM-4系列的开源模型,包括多种版本。
GLM-4的问世,进一步提升了智谱在资本市场的价值,高瓴、红杉、腾讯、顺为均是此时入场。从这个角度来说,GLM-4是极为成功的。
技术方面,走闭源+开源双路线,从单纯卷参数到提升多模态能力、工具化来降低使用门槛,智谱在大模型领域也是走出了一条属于自己的路。
那么,GLM-4为什么没有DeepSeek火呢?近日,由中科院、北大等多家机构发布的一篇论文,可能说明了一些问题。该论文从两个关键要素去评估和量化蒸馏模型的影响,发现包括智谱在内的许多大模型存在过度蒸馏的情况。(详情见:“AI教母”李飞飞祛魅算力讨巧,DeepSeek算法和成本遇争议)
论文中选取了Claude 3.5-Sonnet、豆包Pro-32K、Gemini-Flash-2.0、GLM-4-Plus、Qwen-Max-0919、Deepseek-V3等模型进行测试,其中仅有Claude和豆包的宽松分数和严格分数最低,代表着其受蒸馏影响最小;而GLM-4-Plus、QwenMax和Deepseek-V3是疑似响应数量最多的三个大语言模型,说明它们的蒸馏程度较高。
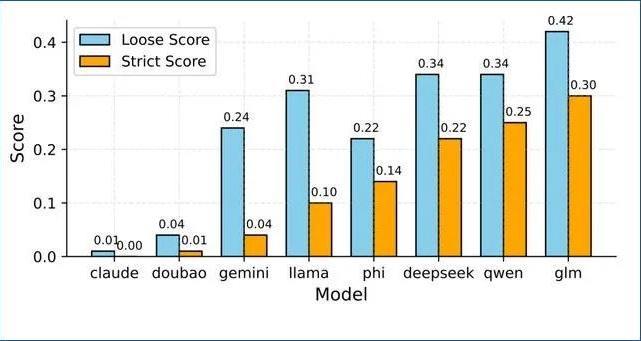
所谓“蒸馏”,是指一种将知识从通用大型语言模型(LLMs)转移到较小模型的技术,目的是创建效率更高且性能卓越的模型。蒸馏技术在大模型训练领域被广泛应用,通常选择开源模型,所以并不能简单理解成“剽窃”。然而该论文指出,过度蒸馏可能会导致模型同质化,并削弱其处理复杂或新任务的稳定性。该论文发表在Github上,感兴趣的读者可以自行阅读。
当然,蒸馏度并不能完全代表一个大模型是否好用,只是其中的一个参考因素。但对于智谱这样深耕大模型数年的企业来说,如何在DeepSeek R1的压力下拿下更多市场,是迫在眉睫的挑战。
商业化保持高增长,但背腹受敌
对于所有AI公司来说,商业化都是悬在头上的达摩克利斯之剑。相对来说,智谱在早期便敲定了C端、B端的商业化方向,并获得了一定的市场份额和收入,同时保持增长。但面对严苛的市场环境,前景仍不算明朗。
智谱COO张帆曾对媒体表示,智谱清言预计2024年收入超过千万元,智谱MaaS开放平台bigmodel.cn API年收入同比增长超过30倍。“一个企服企业如果要做到几个亿的ARR(年度经常性收入),通常需要将近10年的时间,去年我们花几个月的时间就走完了。”张帆表示。
结合C端、B端市场的数据来拆解一下智谱的收入构成,其2024年整体收入保守估计超过1.4亿元。
据AI监测平台“AI产品榜”数据显示,2025年2月AI应用MAU(月活数)全球TOP3分别为ChatGPT、豆包和Nova,DeepSeek紧随其后,月活数约为6181万。智谱清言排名第41位,约为792万,其收入主要来自高级会员订阅。

今年2月,智谱官宣与三星合作,Galaxy S25国行版集成Agentic GLM大模型,智谱清言及清言智能体平台也同步登陆。不过,三星手机在国内市场份额较小,预计年内对月活用户数量的贡献不大。
B端市场的竞争则更加激烈。在这个领域,不仅有“六小虎”等初创公司,百度、阿里、腾讯、字节等巨头同样在争夺该市场。
据IDC调研报告称,中国AI大模型B端目前可以分为解决方案和模型及服务(Maas)两大市场,区别在于前者提供模型框架、大模型、模型训练和调优等服务,支持企业构建和训练自己的大模型;后者是提供以云服务模式交付的全流程AI大模型生命周期工具链以及AI大模型服务,通过API访问、模型中枢或会话接口来提供服务,不包含单独销售的云基础资源层(IaaS)和算力的收入。智谱方面,两大领域均有涉足。
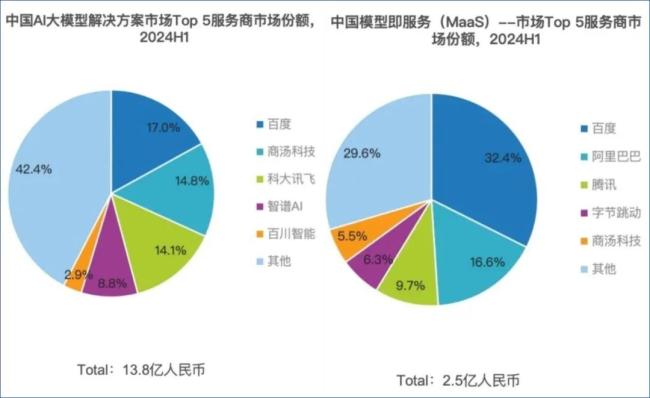
数据显示,2024年上半年,在两大市场中百度均占主导位置,这与其提前十年布局AI市场有关。AI大模型解决方案市场,智谱以约8.8%市场份额拿下第四名;MaaS市场则是大厂的天下,仅有商汤科技挤进前五(“AI四小龙”之首,已于2021年末登陆港股),其他AI独角兽市场份额相对较小。
另据《中国大模型中标项目监测报告(2024)》(来源:智能超参数)显示,2024年中国通用大模型厂商中标前六名分别为:科大讯飞、百度、智谱、火山引擎(字节)、阿里云和腾讯云。其中,智谱中标的数量为32个,披露金额约为1.29175亿元。
据报道称,智谱在B端市场的拓展是非常积极的,也是AI初创企业中最早有收入的公司之一,陈雪松是关键人物之一。这位智谱重金挖来的阿里云原副总裁,曾担任AI公司旷世的高级副总裁、城市业务事业部总经理,主要负责AI安防业务。由于其职业生涯包括国企,现在负责数字政府方面的相关业务,可谓如鱼得水。
另外,智谱在2023年便推出了与华为合作的“智谱-昇腾 AI一体机”系列产品,对于更注重数据安全的国企来说,昇腾芯片显然是比英伟达更好的选择。不过,智谱方面未透露相关产品的具体销售额
综合以上,智谱在2025年面对的挑战是来自多方面的。一是大厂,譬如阿里,近期不仅拿下了与苹果合作的大单,还计划在未来三年内投资至少3800亿元用于建设云计算和AI基础设施,无疑也是瞄准了增长迅猛的MaaS市场。
其次,是DeepSeek为代表的AI新贵。目前,DeepSeek已经涉足政企云端接入、本地部署等业务,第三方硬件企业还在大力推广一体机产品,均与智谱业务重叠。据悉,在相关招标文档中明确提出:“支持市面上主流的信创操作系统和中间件,能和DeepSeek对接,提升智能化水平。”
张鹏想要寻找 “共性需求”
在众多的采访中,张鹏提到了两个重点,分别从技术和市场角度明确了智谱的未来发展方向。当然,这是在DeepSeek出现之前。
技术方面,张鹏表示“不做中国的ChatGPT”,这个观点无疑是具有前瞻性的。张鹏认为,GPT的预训练模式是一项革命性技术,但也并非万能,不一定是AGI的终结方案。“从最早开始我们就定了做通用大模型,我们认为只有一定规模的大模型,才能够实现类人的认知能力的涌现;其次我们希望拥有解决多场景、多任务甚至跨模态的技术。”张鹏说道。
不过,这种认知似乎随着时间推移而发生了变化。在去年8月的采访中,张鹏曾表示:“我对小模型的思考在于,它可能是在应对一些特定问题、特定场景时更有性价比的模型。现在的问题不是模型天花板足够高,而是成本高到大家受不了。”
同时,在被问到对于智谱在C端和B端市场成果是否满意时,张鹏坦言:“取得了一些成绩,但要说完全满意还谈不上。”他对智谱在市场方面的期许,是“找到用户的所谓共性需求,挖掘痛点,用技术去解决,再找到最好的性价比”。
据接近智谱的人士透露,智谱内部从技术层面上颇为认可DeepSeek R1的技术方向,即深度思考,内部已经开始训练下一代模型。
从最新融资来看,智谱作为“国家队”的含金量并未降低;DeepSeek对AI算力模式的颠覆,已经开始影响投资人对“六小龙”的未来评估。有行业人士表示,如果没有DeepSeek,智谱目前IPO的估值也许有望达到四五百亿甚至更高。
推荐阅读



阿里、腾讯等豪门云集清华系大模型,智谱AI再获30亿融资
大模型浪潮持续翻涌,作为国产AI六小龙之一的智谱AI自然成为了较为优质的投资标的之一。

平治信息擘画算力新图景:与智谱AI达成合作,连续签署多个大单
12月4日,平治信息(300571)官网发布消息,公司与智谱AI达成合作,加速构建智算服务生态。


酒业进入“数智化”时代
2024年,中国酒业经历了深刻的变革,在浪潮汹涌的行业变局中,“数智化”正逐渐成为酒业发展的关键驱动力,引领着酒业迈向一个全新的时代。

探寻浦发银行的“数智化”经营之道
在充满挑战的2024年,浦发银行靠着坚定的战略、稳健的经营,交出了一份亮眼的半年度经营业绩,也让诸多资金看到了真实的价值。