OpenAI 复制吉卜力,大模型正在吞噬一切产品?

新产品发布两天后,在 OpenAI 创始人山姆·阿尔特曼(Sam Altman)的推文下,有人祝贺他十年努力终于带来了 AGI——社交网络上全是吉卜力图像 “All Ghibli Images”。
3月26日,OpenAI更新GPT-4o文生图功能。付费用户可以在ChatGPT直接调用4o生成、修改图片,不再需要使用OpenAI的文生图模型DALL-E。仅仅一天时间,近年影响较大的照片和meme图都被4o重做了一遍,最流行的就是宫崎骏的画风。
人人都用生成吉卜力画风不仅仅因为宫崎骏对世界的卓绝贡献,也因为OpenAI的引导——阿尔特曼在GPT-4o新功能发布的直播里选择生成吉卜力风格的三人自拍照。但其实GPT-4o生成其他风格效果通常也不错。
文生图已经不新鲜,此前也有文生图产品能实现风格化效果。比如 Midjourney 年付费用户可以改照片风格,Stable Diffusion 也有专门训练成吉卜力风格的模型,Gemini 2.0 半个月前也增强了文生图功能
但GPT-4o在多个领域明显超过所有对手,比如图像中的文字(尤其是英文)基本不再是乱码。以图生图时,画面细节更符合现实情况,修改图片时画面细节能保证较高的一致性。
GPT-4o对技术普及影响最大的可能是控制更容易也更精确,整个过程不再需要复杂、精确的提示词,像平时说话一样给修改建议就行。
文生图开源模型 Stable Diffusion 在 2022 年发布。需要制图、画插画的行业很快就将它引入工作。但 Stable Diffusion 本身不够可控,于是 LoRA、ControlNet 等技术被发明出来,新的创业公司应运而生,帮助完善产品、提供服务,搭建起一套实际可用的工作流程。
“(GPT-4o)直接干翻了之前很多创业公司的产品。”资深用户体验设计师章萧醇说。“他们花了那么多时间、人力、投资人的钱,调优的算法、工作流、模型,直接被一次大模型的更新取代了。”
“因为大模型变得过于强大,一种新型编程方式正在兴起。”AI 科学家安德烈·卡帕斯(Andrej Karpathy)把它称为 “Vibe Coding(氛围编程)”,“只是看东西、说话、运行程序和复制粘贴,就能开发程序,这套流程大多数时候都能正常工作。”
而 GPT-4o 的文生图功能就像是 Vibe Painting。
技术细节有限,推论是OpenAI靠底层能力提升
不论是Google还是OpenAI,发布新的文生图功能时,都没有介绍技术细节,以至于许多人去问ChatGPT,OpenAI到底是怎么做到的。
相对权威的技术介绍,是 OpenAI 的研究员加布里埃尔·吴(Gabriel Goh)在直播中提到的两点:
全模态的GPT-4o是这项功能的基础,它有生成各种类型数据如文本、图像、音频和视频的能力。
采用自回归(autoregressive)方法(根据已经生成的内容来预测下一个元素)——从左到右、从上到下顺序生成图像,类似于文本的书写方式——而不是大多数图像生成模型(如 DALL-E)使用的扩散模型(Diffusion Model)技术,一次性创建整个图像,然后降噪提高清晰度。
GPT-4o是OpenAI去年5月发布的大模型,与GPT-4.5、DeepSeek-V3等专注文本能力的模型不同,它用文本、视觉、音频等数据训练。OpenAI称,它可以处理用户输入文本、音频、图像或视频的组合内容,也可以反馈文本、音频、图像或视频组合内容——不过现在GPT-4o还没有完全具备上述能力。
OpenAI新发布的文生图功能,是其沿着GPT-4o技术路线发掘到的新成果。
清华大学 NICS-EFC 实验室专注文生图研究的博士生赵天辰对《晚点 LatePost》说,GPT-4o 用自回归技术可能不是图像生成能力大幅提升的核心原因,而是 OpenAI 大幅提升了“文本-图像对齐”(text-image alignment)能力。
行业内惯用的文生图模型,如Midjourney、DALL-E系列,生成图像时会用到多个组件:先理解用户输入的提示词,转换为文本特征,再聚合对应的图像特征,最后生成图像。
赵天辰说,目前开源的文生图模型,引入文本控制信号上,存在以下不足:
一般都采用较小的模型提取文本特征(CLIP/T5),文本的理解能力会受到“不够强”的文本制约,损失一些文本信息。
引入控制信号的方式“相对朴素”,用注意力机制融合文本特征与图像特征,即使文本特征足够好,也无法保证图像特征能够准确遵循文本特征。
许多开发文生图工具的公司或者使用文生图工具的设计师,往往用精心调教的提示词、层层叠加的插件、环环相扣的模型链弥补缺陷,把它变成可用的工具。
OpenAI 用 GPT-4o 提升了模型的理解文本特征和提示词的能力。“如果我去画一幅图,虽然能力有限,但也会用自己积累的知识完成它”。ChatGPT 多模态产品负责人杰基·香农(Jackie Shannon)说,“大模型有通用知识,当你用 GPT-4o 生成一张牛顿棱镜实验的图像时,你不需要解释那是什么,就能得到相应的结果。”
赵天辰推测,OpenAI模型展示出的惊艳文本遵从能力,尤其是能准确把握文本描述中多个对象,以及形容词和位置关系,可能很难通过传统的单次文生图“端到端”达成。在现有模型中,如果提示词中有很多颜色,比如“蓝色的帽子”和“红色的衣服”,直接交给模型端到端生成,结果可能是衣服和帽子都有蓝有红,颜色混在一起。
GPT-4o基本不会有类似错误。他认为可能采用了“组合-分解式”的生成方案,比如生成一个人在左边,再生成一条狗在右边,然后把这些图叠起来,最后整体生成一遍,把它们融合在一起。
从编程到图片生成,大模型试图吞噬依赖它的应用
编程是大模型最早规模商业化的场景。2021 年 OpenAI 推出 GPT-3 不久,微软就用它做出了 GitHub Copilot。
就像它的名字那样,受限于模型能力,GitHub Copilot 很长时间只能作为辅助编程工具,它最好用的场景是补全代码和 Debug,程序员还要做不少引导工作。
随着大模型能力持续提升,GitHub Copilot 在 2023 年用上新模型后,年化收入迅速突破 1 亿美元。行业内也诞生了 Cursor、甚至 Devin 这样的产品。它们集成了 Anthropic、OpenAI 的最新模型,编写简单的代码多数情况都不需要程序员干预,但写复杂的代码还是需要程序员引导。
Cursor 等产品还面临一批竞争对手——它们依赖的大模型公司,如 Anthropic、OpenAI 等。它们在持续提高大模型本身的编程能力,每一次更新都有可能削减 Cursor 等产品的价值。比如编程竞赛 CodeForces 的测试,OpenAI 的 o3 的编程能力已经达到了 Top 200 人类程序员的水平。虽然它并不代表实际的编程水平,但证明了大模型本身的潜力。
这就是安德烈·卡帕斯提出 Vibe Coding 的背景,编程 “几乎不用碰键盘”,收到报错信息时,只用复制粘贴进去,通常就能解决问题。
硅谷创业孵化器 YC CEO 陈嘉兴(Garry Tan)接受采访说,创业者不再需要第一个 50 或 100 人的工程师团队,可以用 10 个人建立每年赚 1000 万或 1 亿美元的公司。最新一期 YC 创业营中,有 1/4 的公司采用 Vibe Coding, 95% 的代码由大模型直接生成。
GPT-4o也推动文生图沿着类似的趋势发展。过去的文生图模型可以生产出来以假乱真的图像,但还是有足够高的门槛——更懂模型的人、更有审美的人、更会写提示词的人,再自己训练模型、找插件,可能还得动手PS一下,才能得到理想的图。
现在模型本身变成了一个聪明的专业人士。
“我曾引以为傲的复杂工作流程——精心调教的提示词、层层叠加的插件、环环相扣的模型链——如今都被一个简单对话界面所取代。”资深产品设计师歸藏说,他认为这会是AI领域的常态,“复杂工程化注定会被模型碾碎”。
GPT-4o 图片生成功能推出后,文生图领域明星创业公司 Midjourney CEO 创始人大卫·霍尔兹(David Holz)在公司举办的活动中说,OpenAI 只是 “在试图筹钱,并以一种有毒的方式竞争,它只是一个梗而不是创意工具”,未来 Midjourney 还是会基于社区的反馈驱动改进,而不是外部的市场压力。
Midjourney的成长得益于OpenAI在2021年推出的文本-图像对齐模型CLIP。在后续的产品迭代中,Midjourney用更精细的工程能力,对生成图像审美的苛刻关注,训练了效果更好的模型,仅靠Discord就迅速获得每年数亿美元的收入。类似的例子还有AI搜索应用Perplexity。
如果大模型本身的能力进步有限,就是这类创业公司的机会——他们针对垂直领域的功能优化或者训练小模型,可以更好地发挥大模型效果。
但如果大模型能持续进步,许多精心调教后的产品能力成为庞大模型的一部分,用户直接说几句话就能实现想要的效果,那大模型本身就是终极产品。能投入组建大团队、巨资训练模型的公司才有资格参与大模型性能的比拼。
技术演进偏向哪一端,最终将决定AI生态的未来更偏向大公司还是新锐团队。
推荐阅读


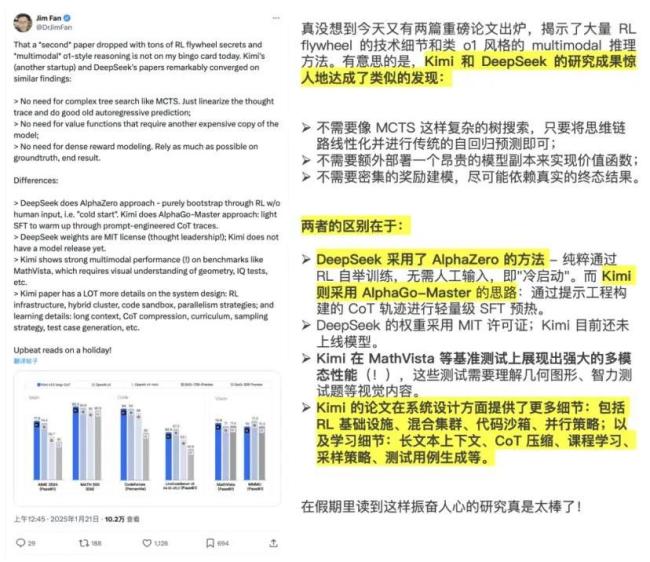
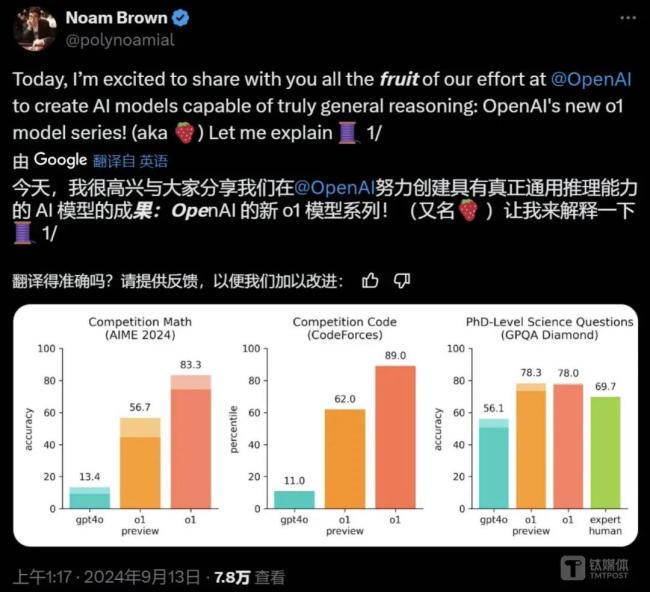
OpenAI奥尔特曼罕见发长文:超级AI可能在几千天内实现
在奥尔特曼看来,深度学习路线将会成为进入超级智能时代的钥匙。而在这个过程中,降低算力成本和建立基础设施对于普及AI至关重要。


OpenAI GPT-5、百度文心一言相继免费,AI 行业迈向生态竞争新时代?
百度宣布文心一言将取消所有用户端的付费门槛,其新推出的“深度搜索”功能也将同步免费开放。





巨头抢滩、资本沸腾,AI智能体如何跨越「幻觉」陷阱?
Manus的出现,激起了科技与资本市场的双重震荡,一时间AI Agent相关概念股集体大涨,阿里、谷歌、微软等科技巨头密集发布智能体研发计划......

封锁下成长起来的中国AI“三叉戟”,为何让大洋彼岸的硅谷恐慌?
无论是Deepseek的开源模型打破“算力垄断”,还是萝卜快跑用1/7的成本碾压Waymo,中国AI的崛起直指美国技术霸权的软肋——当硅谷沉迷于资本堆砌的军备竞赛时,中国企业用工程化创新和场景化落地开辟了一条新赛道。